HTTP in Python: aiohttp vs. Requests
NOTE: this blog post is about async programming in Python 3.5, but a few things have changed since then. In January 2019, Brad Solomon wrote a great article about async programming in Python 3.7 – Async IO in Python: A Complete Walkthrough.
I recently attended PyCon 2017, and one of the sessions I found most interesting was Miguel Grinberg’s Asynchronous Python for the Complete Beginner. I’ve been meaning to dig into the new asyncio features that were added in Python 3.4 for some time, but other than a bit of reading on the topic (such as Brett Cannon’s excellent How the heck does async/await work in Python 3.5?), I hadn’t really done anything with the new async capabilities.
Miguel’s session was a great overview, and motivated me to try out some things when I got back to Seattle late on Sunday. Most of the examples I’ve seen use sleep() for the “what to wait for” part of the demo code, and I wanted to try something more realistic such as waiting on HTTP requests. I love the Requests library and use it constantly, but after a bit of research I found that Requests has a synchronous approach baked right in, so it’s not the right API for doing asynch HTTP requests. There are several popular approaches to asynch HTTP requests in Python, and I decided to give aiohttp a whirl, since it’s designed to work with asyncio.
TLDR version: aiohttp/asyncio works great, and I posted a Gist of a simple demo at https://gist.github.com/dmahugh/b043ecbc4c61920aa685e0febbabb959
The rest of this post is a walkthrough of the demo. The simple scenario I used was reading web pages from several big tech company home pages:
if __name__ == '__main__':
URL_LIST = ['https://facebook.com',
'https://github.com',
'https://google.com',
'https://microsoft.com',
'https://yahoo.com']
demo_sequential(URL_LIST)
demo_async(URL_LIST)
For the sequential part of the demo, I used requests.get() to read the pages in a loop, and printed out the time for each request and the total:
def demo_sequential(urls):
"""Fetch list of web pages sequentially."""
start_time = default_timer()
for url in urls:
start_time_url = default_timer()
_ = requests.get(url)
elapsed = default_timer() - start_time_url
print('{0:30}{1:5.2f} {2}'.format(url, elapsed, asterisks(elapsed)))
tot_elapsed = default_timer() - start_time
print(' TOTAL SECONDS: '.rjust(30, '-') + '{0:5.2f} {1}'. \
format(tot_elapsed, asterisks(tot_elapsed)) + '\n')
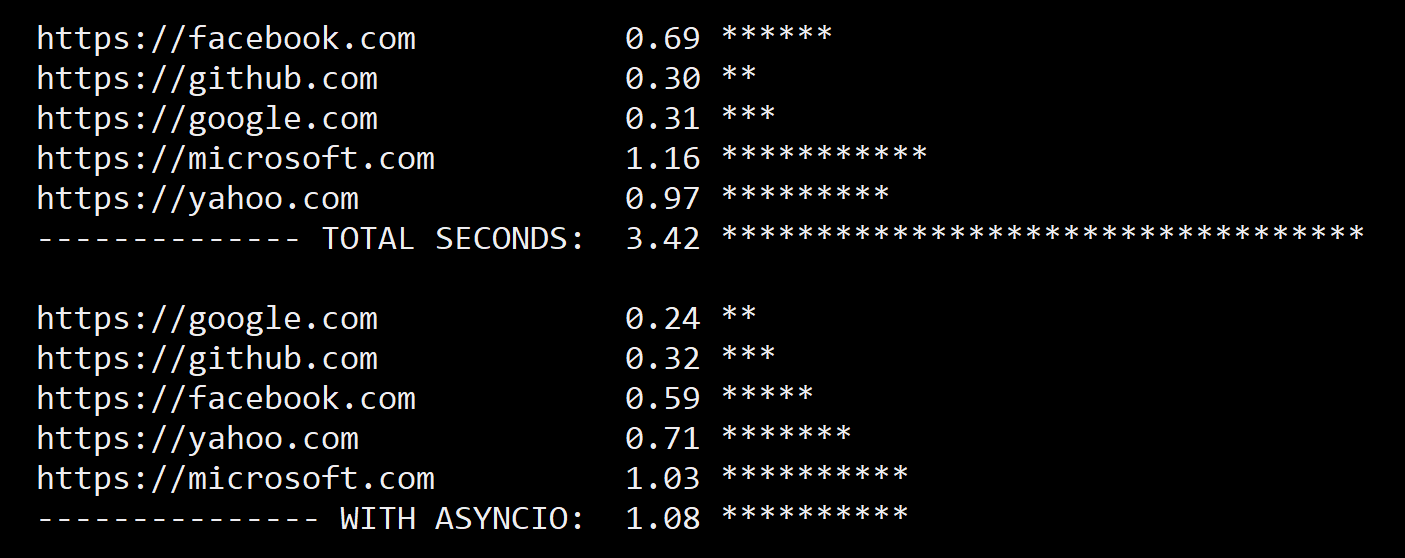
Since that example runs sequentially, the total time is just the sum of the times for each page:
https://facebook.com 0.57 ****
https://github.com 1.47 *************
https://google.com 0.38 **
https://microsoft.com 1.12 **********
https://yahoo.com 0.54 ****
-------------- TOTAL SECONDS: 4.09 ***************************************```Next I tried retrieving the same pages asynchronously with aiohttp. The basic concept is that you need to get an event loop, then schedule the execution of coroutines to fetch the pages, then run the loop until all of the pages have been retrieved. These three lines of code in demo_async() do exactly that:
loop = asyncio.get_event_loop() # event loop
future = asyncio.ensure_future(fetch_all(urls)) # tasks to do
loop.run_until_complete(future) # loop until done
The fetch_all(urls) call is where the HTTP requests are queued up for execution, by creating a task for each request and then using asyncio.gather() to collect the results of the requests. Here’s the code:
async def fetch_all(urls):
"""Launch requests for all web pages."""
tasks = []
fetch.start_time = dict() # dictionary of start times for each url
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task) # create list of tasks
_ = await asyncio.gather(*tasks) # gather task responses
Note the async with context handler, which creates a single ClientSession object that is used for all requests to take advantage of connection pooling.
Also note the use of a start_time dictionary (attached as a property of the function itself) to track the start time for each request. We don’t know the order in which the requests will finish, so this dictionary is used in the fetch() function to determine the elapsed time for each request.
Finally, the fetch() function uses async with again, but this time with the session’s get() method to asynchronously retrieve each page and then display the elapsed time:
async def fetch(url, session):
"""Fetch a url, using specified ClientSession."""
fetch.start_time[url] = default_timer()
async with session.get(url) as response:
resp = await response.read()
elapsed = default_timer() - fetch.start_time[url]
print('{0:30}{1:5.2f} {2}'.format(url, elapsed, asterisks(elapsed)))
return resp
The queued requests run in parallel, and the total elapsed time is simply the longest-running request plus a bit of overhead for task switching:
https://google.com 0.29 *
https://facebook.com 0.43 ***
https://github.com 0.48 ***
https://yahoo.com 0.51 ****
https://microsoft.com 1.21 ***********
--------------- WITH ASYNCIO: 1.27 ***********That’s a little better than a 3X performance boost, and for this set of 5 web pages I found that the async approach is usually around 2x-5x faster. That’s a great perf improvement, and it would probably be even greater for API calls that are more resource-intensive on the server side. I’ll do a similar comparison for API calls against Microsoft Graph soon, and post some benchmarks for that as well.
Async definitely adds some code complexity relative to traditional sequential processing (about a dozen extra lines of code in this simple example), but when you’re doing work that requires waiting on external processes, it can be a great way to keep the local CPU busy and productive while waiting on other resources. Async FTW!